테크
2025. 12. 01
AWS에서 LLM과 음성 AI 서비스 연동하기
Bedrock, Polly, Transcribe 실제 연동 과정을 통해 얻은 경험

“우리의 서비스와 AI를 결합하면 어떤 새로운 기능을 만들 수 있을까?”
최근 비누팀에서는 이 질문을 중심으로 다양한 실험과 논의가 활발하게 이루어지고 있습니다. 그런 흐름 속에서, 지난 9월 실제로 다양한 AI 기술을 실험하고 적용해 볼 수 있는 사내 해커톤이 개최되었습니다.
이번 해커톤에는 사내의 프로덕트 직군의 모든 멤버들이 참여해 음성 인식, 대화형 AI, 텍스트 생성 등 여러 기술을 다루어 보았는데요. 그중에서도 제가 참여한 팀은 AWS의 AI 서비스들을 조합해 음성 기반 대화 시스템 구축을 시도했고, 예상보다 복잡한 문제들과 마주하게 되면서 흥미로운 포인트들이 많았습니다.
겉으로 보기에는 “음성을 텍스트로 바꾸고, LLM에 전달하고, 다시 음성으로 변화면 되겠지”라고 생각하기 쉽지만, 실제로 자연스러운 대화를 만들기 위해 고려해야 할 요소들은 훨씬 더 많았습니다.
프로젝트를 진행하면서 해결해야 할 기술적 도전 과제들은 다음과 같았습니다.

이번 글에서는 저희가 이 방식을 어떻게 구현하고, 어떤 점에서 도움이 되었는지 자세히 공유해 보려고 합니다.
1. 음성 대화 시스템을 구성하는 AWS AI 서비스
먼저 음성 기반 AI 대화 시스템을 구축할 때 활용할 수 있는 3가지의 AWS 서비스를 살펴보고, 각 서비스의 역할과 선택 기준을 정리해보겠습니다.
1️⃣ Bedrock | LLM 모델 관리 및 호출
Bedrock은 Amazon, Anthropic, Meta 등 여러 회사의 foundation model을 단일 API로 통합 제공하는 완전관리형 LLM(Large Language Model, 대규모 언어 모델) 플랫폼입니다. 모델 운영·스케일링·보안 등을 AWS가 책임지기 때문에, 개발자는 모델 선택과 프롬프트 설계에만 집중할 수 있습니다.
이번 프로젝트에서는 한국어 처리 품질과 긴 컨텍스트 유지 능력이 뛰어난 Claude 4 Haiku를 사용했습니다.
☑️ Claude 4 Haiku를 선택한 이유
최신 모델인 Claude 4.0 Sonnet이 더 높은 성능을 제공하지만, 실제 서비스에서는 성능과 비용의 균형이 매우 중요합니다. 여러 테스트를 진행한 결과 다음과 같은 이유로 Claude 4 Haiku가 최적의 선택이었습니다.
충분한 한국어 품질: 자연스러운 대화와 문맥 이해가 안정적으로 가능
낮은 응답 지연 시간: 음성 대화 서비스에서 핵심인 빠른 응답
비용 효율성: Sonnet 대비 토큰 비용 약 66% 절감
운영 안정성: 실제 프로덕션 환경에서 검증된 모델
특히 음성 기반 대화는 한 세션에서 수십 턴의 대화가 발생하기 때문에 토큰 사용량이 많습니다. 시뮬레이션 결과, Claude 4 Haiku를 사용하면 월 비용을 약 40% 절감하면서도 사용자 체감 품질 차이는 거의 없었습니다.
2️⃣ Transcribe | 음성 → 텍스트
Transcribe는 사용자의 음성을 텍스트로 변환하는 실시간 음성 인식(STT, Speech-to-Text) 서비스입니다. 한국어 인식 정확도가 높고, 스트리밍 기반 또한 스트리밍 기반으로 낮은 지연 시간을 제공해 대화형 서비스에 적합합니다. 또한 자동 문장 부호, 타임스탬프, 포맷팅 기능을 지원해 후처리 부담을 줄일 수 있습니다.
3️⃣ Polly | 텍스트 → 음성
Polly는 LLM이 생성한 텍스트를 자연스러운 음성으로 변환하는 TTS(Text-to-Speech**)** 서비스입니다. Neural TTS 기술을 기반으로 실제 사람과 유사한 발화를 생성하며, SSML을 통한 속도·톤·강세 조절도 지원해 사용자 경험을 세밀하게 다듬을 수 있습니다.
이렇게 각각의 서비스가 역할을 수행하면, 사용자와 AI 간 실시간 음성 대화가 가능해지게 됩니다.
사용자 음성 → [Transcribe] → 텍스트 → [Bedrock] → AI 응답 → [Polly] → 음성 출력
2. Langchain으로 긴 대화 컨텍스트 관리하기
여기서 놓치면 안 될 포인트가 있습니다. LLM은 토큰 수 제한이 있기 때문에, 연속적인 대화나 방대한 문서를 다룰 때 긴 컨텍스트 관리가 항상 난관으로 작용합니다.
이에 저희는 효율적인 컨텍스트 관리를 위해 LangChain에서 제공하는 세 가지 주요 기법인 Stuff, Map-Reduce, Refine을 심층적으로 검토했습니다. 대화의 맥락을 안정적으로 유지하고 토큰 제한을 효과적으로 우회하기 위한 전략으로 각 기법의 특징을 비교한 결과, 과연 어떤 방식이 채택되었을까요?
1️⃣ Stuff 방식
가장 단순하고 직관적인 방식입니다. 모든 문서나 메시지를 하나의 긴 문자열로 합쳐서 한 번에 LLM에 전달합니다.
[청크 1 + 청크 2 + 청크 3 + ... + 청크 N] → LLM → 응답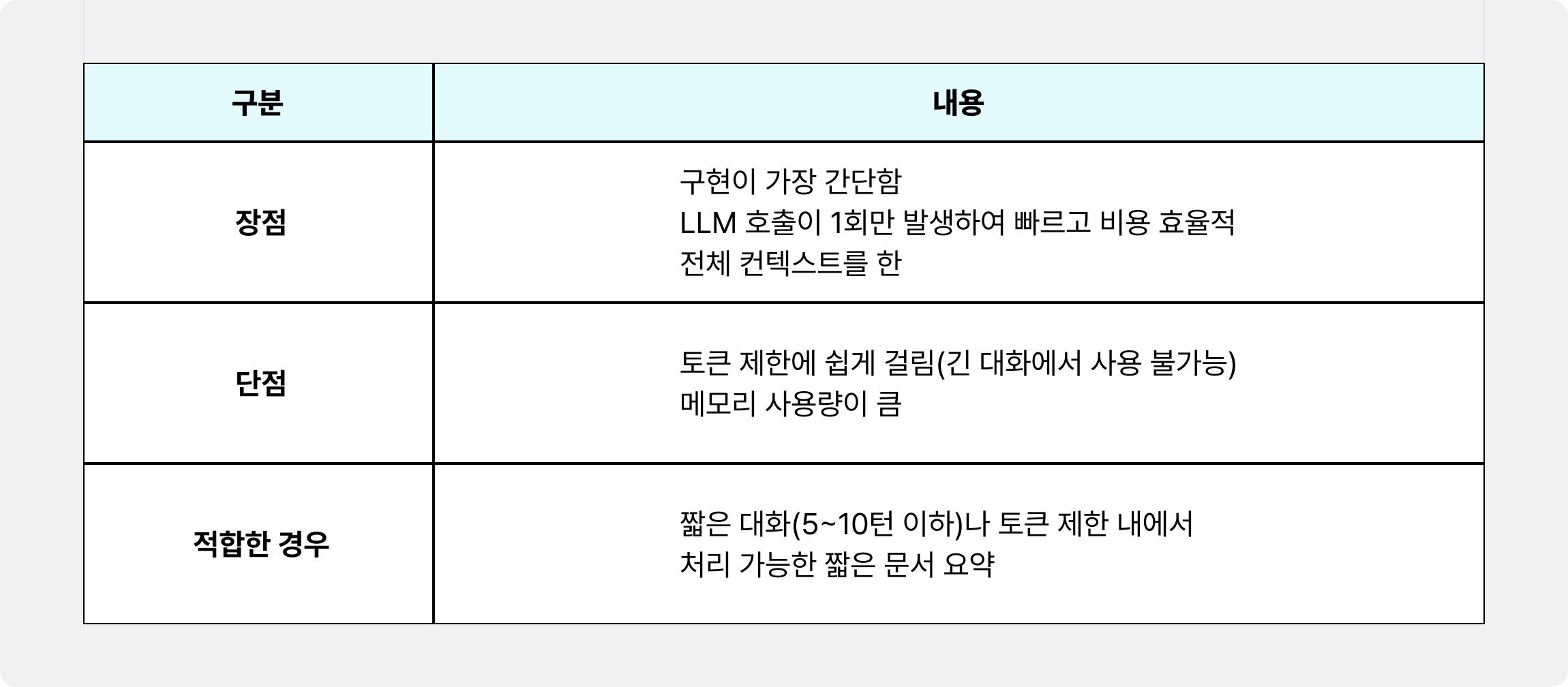
2️⃣ Map-Reduce 방식
각 청크를 독립적으로 처리하여 개별적인 결과를 얻은 후, 이 결과들을 다시 모아 최종적으로 한 번 더 LLM에 전달하여 병합하고 응답을 생성하는 방식입니다.
청크 1 → LLM → 결과 1
청크 2 → LLM → 결과 2 } → [결과 1 + 결과 2 + 결과 3] → LLM → 최종 응답
청크 3 → LLM → 결과 3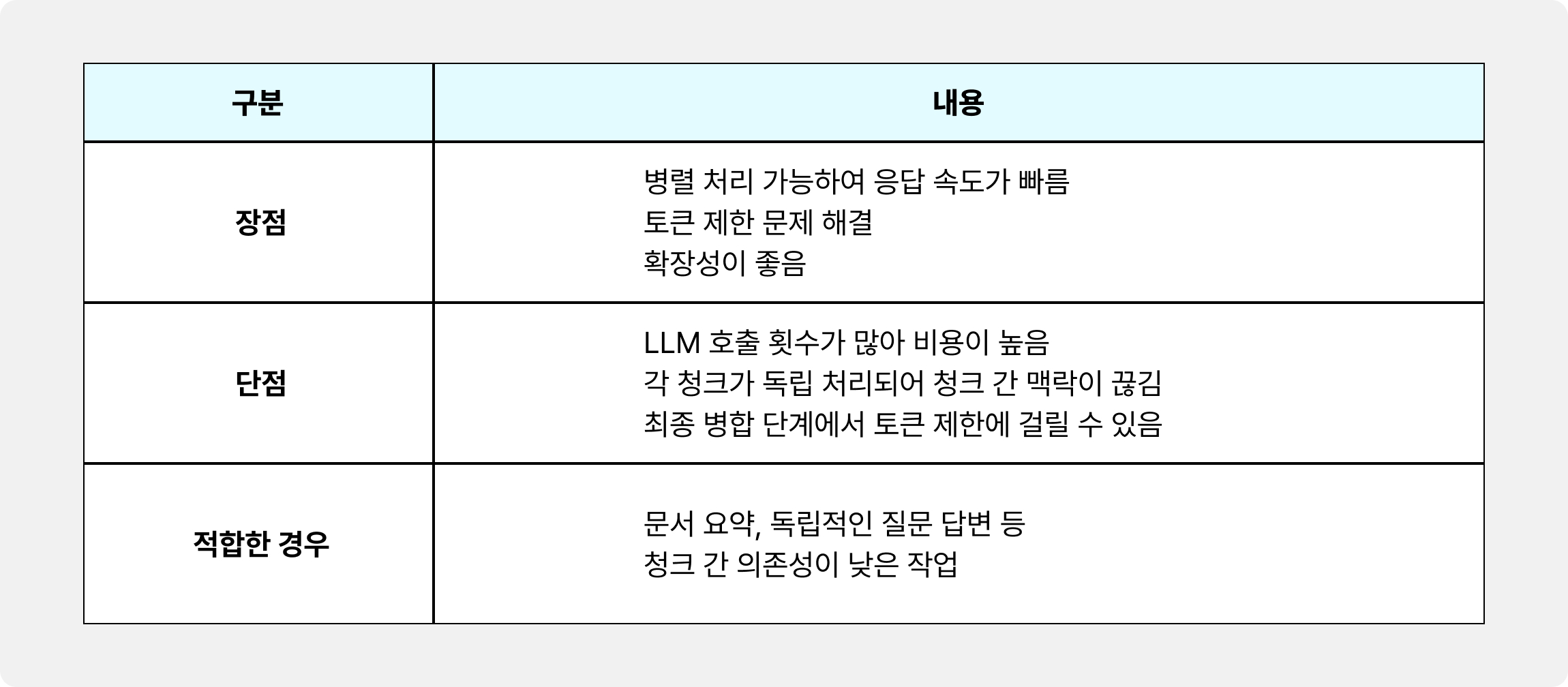
3️⃣ Refine 방식
순차적으로 청크를 처리하면서, 다음 청크를 처리할 때 이전 단계에서 생성된 응답을 계속 개선하는 방식입니다.
청크 1 → LLM → 응답 1
청크 2 + 응답 1 → LLM → 응답 2 (개선)
청크 3 + 응답 2 → LLM → 응답 3 (최종)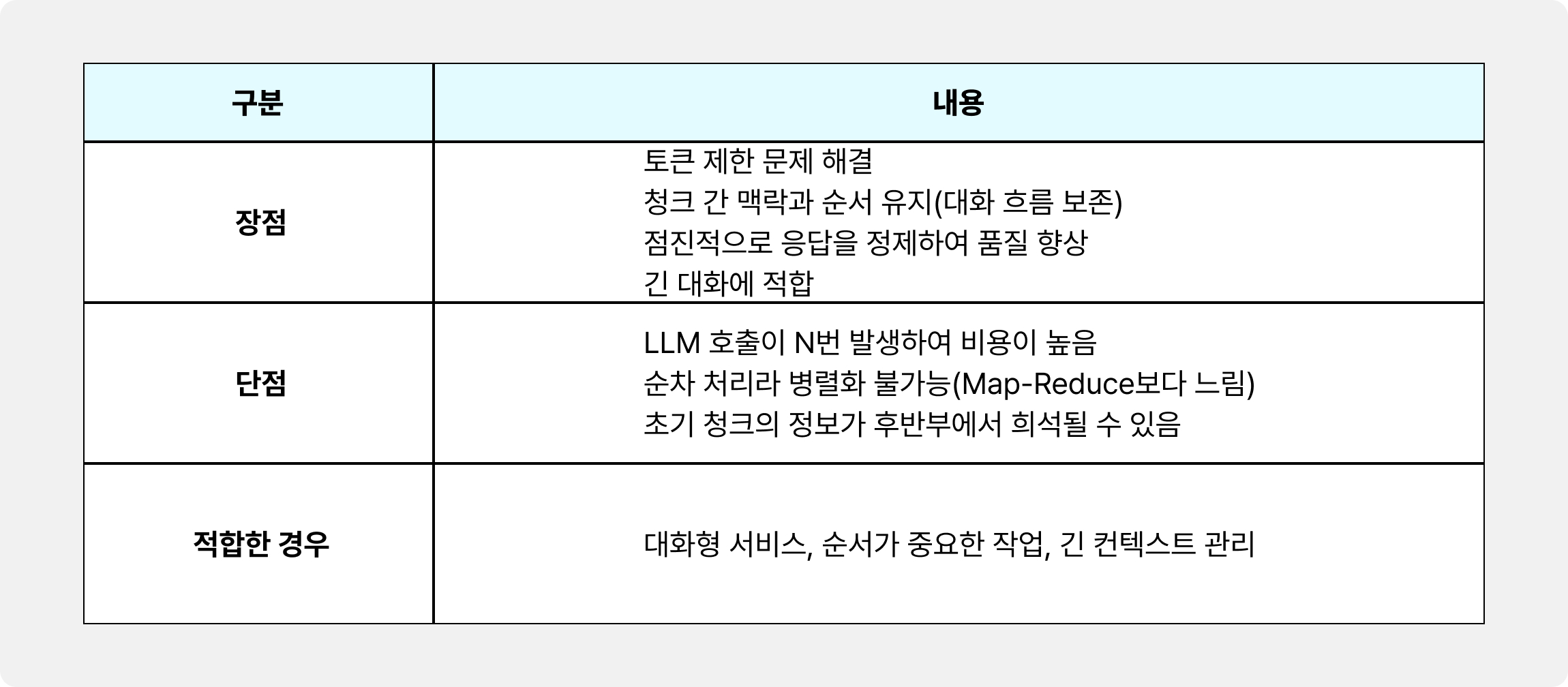
☑️ 한 눈에 비교하기
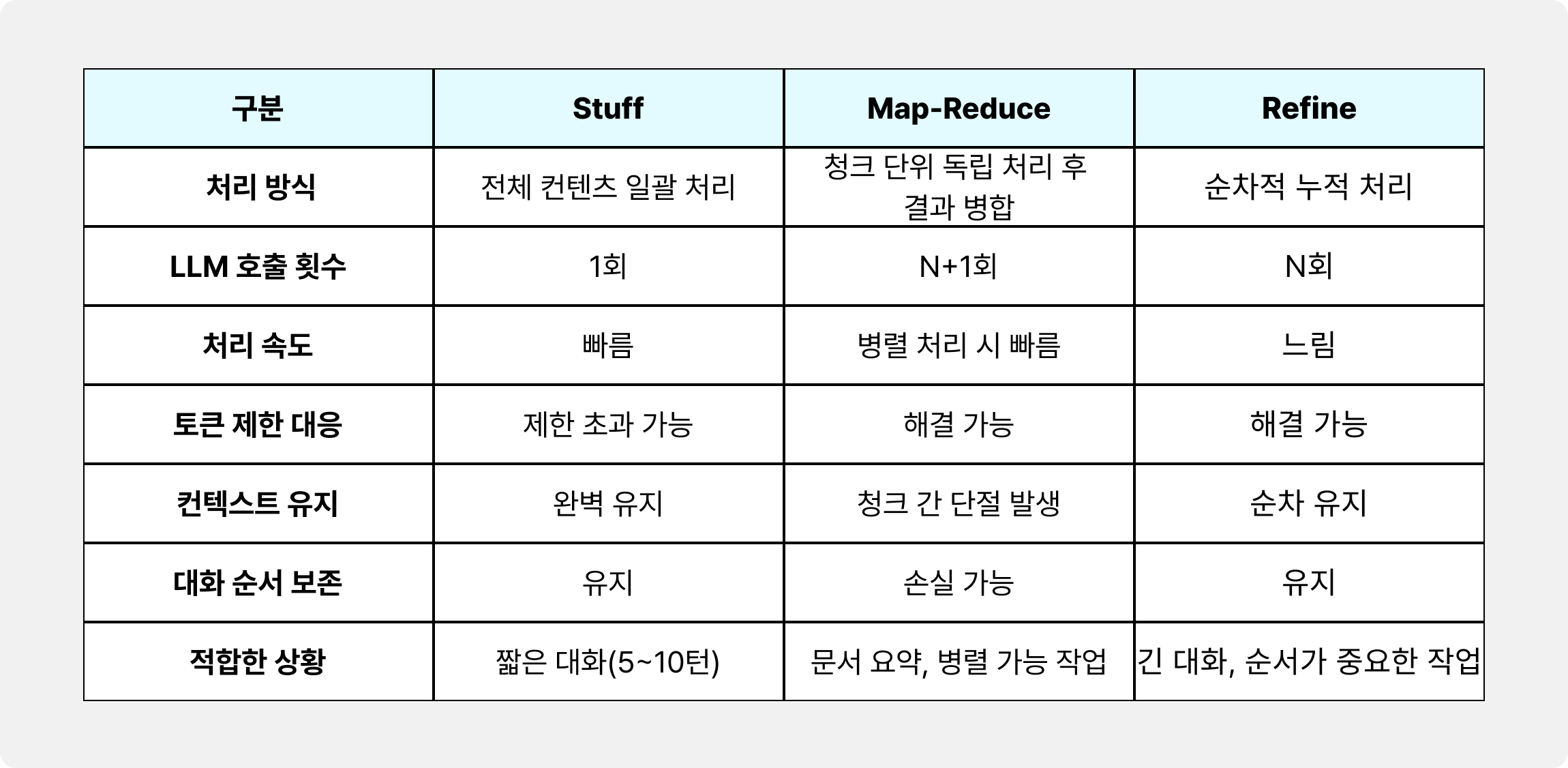
각 방식의 장단점을 면밀히 분석한 끝에 최종 선택지는 자연스럽게 정해졌습니다. 음성 대화 서비스에서는 대화의 연속성, 긴 세션 지원, 안정적인 컨텍스트 유지가 핵심이기 때문입니다.
Map-Reduce는 병렬 처리로 속도는 빠르지만 대화의 흐름이 끊기기 쉬웠고, Stuff는 토큰 한계로 인해 긴 대화를 제대로 다룰 수 없었습니다. 반면 Refine 방식은 매 턴마다 기존 컨텍스트를 정교하게 반영해 확장하기 때문에 이러한 요구사항에 가장 부합했습니다. 실제로 10턴 이상의 장기 대화 실험에서도 Refine 방식은 초기 질문의 핵심 정보를 끝까지 유지하면서, 전체 토큰 예산 안에서 안정적으로 동작하는 모습을 확인할 수 있었습니다.
3. 음성 대화 서비스 구현하기
이제 컨텍스트 관리의 핵심 전략이 Refine 방식으로 확정된 만큼, 이 기반 위에서 실제 음성 기반 대화 시스템의 기본 구조를 단계별로 구현해 보겠습니다.
1️⃣ 환경 설정
먼저 구현에 사용할 핵심 패키지들부터 설치합니다. LLM 연동을 위한 Bedrock SDK와 음성 처리를 위한 Polly, Transcribe SDK, 그리고 핵심인 LangChain 라이브러리가 필요합니다.
npm install @aws-sdk/client-bedrock-runtime @aws-sdk/client-polly @aws-sdk/client-transcribe
npm install langchain @langchain/community @langchain/aws
AWS 클라이언트 초기화 시에는 각 서비스별로 클라이언트를 분리하고, 보안을 위해 리전과 인증 정보는 환경변수로 관리하는 것이 일반적입니다.
2️⃣ Bedrock과 LangChain 연동
이제 LangChain의 BedrockChat 클래스를 이용해 Claude 4 Haiku 모델과 연결합니다. 이 클래스를 사용하면 Bedrock과의 통신을 매우 간편하게 처리할 수 있습니다.
import { BedrockChat } from '@langchain/community/chat_models/bedrock';
import { HumanMessage, AIMessage, SystemMessage } from '@langchain/core/messages';
// 모델 초기화
const model = new BedrockChat({
model: 'anthropic.claude-4-haiku',
region: 'us-east-1',
modelKwargs: {
temperature: 0.7,
max_tokens: 2048,
},
});
// 대화 히스토리를 포함한 응답 생성
async function generateResponse(userMessage: string, conversationHistory: Array<{role: string; content: string}>) {
const messages = [
new SystemMessage('당신은 친절한 AI 어시스턴트입니다.'),
...conversationHistory.map(msg =>
msg.role === 'user' ? new HumanMessage(msg.content) : new AIMessage(msg.content)
),
new HumanMessage(userMessage),
];
const response = await model.invoke(messages);
return response.content as string;
}
코드에서 볼 수 있듯이, LangChain이 제공하는 구조화된 메시지 타입(SystemMessage, HumanMessage, AIMessage)을 사용하면 LLM에게 대화 히스토리를 더욱 명확한 역할 기반으로 전달할 수 있습니다.
3️⃣ Polly를 활용한 음성 합성
LLM이 생성한 텍스트 응답은 Polly를 통해 자연스러운 한국어 음성으로 변환됩니다. 저희는 ‘Seoyeon’ 목소리를 선택했고, 고품질의 Neural TTS 엔진을 사용했습니다.
import { SynthesizeSpeechCommand, VoiceId, Engine } from '@aws-sdk/client-polly';
import { pollyClient } from '../config/aws.config';
async function synthesizeSpeech(text: string) {
const command = new SynthesizeSpeechCommand({
Text: text,
OutputFormat: 'mp3',
VoiceId: VoiceId.Seoyeon, // 한국어 여성 음성
Engine: Engine.NEURAL, // Neural TTS 사용
LanguageCode: 'ko-KR',
});
const response = await pollyClient.send(command);
return response.AudioStream; // 음성 데이터 스트림 반환
}
여기서 주의할 점은 Polly에는 3,000자 제한이 있다는 것입니다. 따라서 긴 텍스트를 처리할 때는 반드시 청크로 나누어 합성해야 합니다. 또한, SSML(Speech Synthesis Markup Language)을 활용하면 음성의 속도, 강조, 문장 간 숨 고르기 등을 개발자가 세밀하게 제어할 수 있습니다.
4️⃣ Transcribe로 음성 인식
사용자의 음성 입력을 텍스트로 바꾸는 역할은 Transcribe가 담당합니다. 파일을 S3에 업로드한 후, Transcribe의 비동기 작업 방식으로 파일을 처리했습니다.
import { StartTranscriptionJobCommand, GetTranscriptionJobCommand } from '@aws-sdk/client-transcribe';
import { transcribeClient } from '../config/aws.config';
async function transcribeAudio(audioFileUri: string, jobName: string) {
// 1. Transcription 작업 시작
await transcribeClient.send(new StartTranscriptionJobCommand({
TranscriptionJobName: jobName,
LanguageCode: 'ko-KR',
MediaFormat: 'mp3',
Media: { MediaFileUri: audioFileUri },
}));
// 2. 작업 완료 대기 (폴링 방식)
while (true) {
const { TranscriptionJob: job } = await transcribeClient.send(
new GetTranscriptionJobCommand({ TranscriptionJobName: jobName })
);
if (job?.TranscriptionJobStatus === 'COMPLETED') {
// 3. 결과 파일에서 텍스트 추출
const response = await fetch(job.Transcript!.TranscriptFileUri!);
const data = await response.json();
return data.results.transcripts[0].transcript;
}
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
코드를 보시면, 작업 시작 후 완료될 때까지 폴링(Polling) 방식으로 대기하는 것을 알 수 있습니다. 만약 서비스에서 실시간 응답 속도가 중요하다면, @aws-sdk/client-transcribe-streaming을 사용해 스트리밍 방식으로 전환할 수 있습니다.
5️⃣ Refine 체인으로 컨텍스트 관리하기
이제 이 프로젝트의 핵심 알고리즘인 Refine 방식의 대화 컨텍스트 관리를 구현할 차례입니다. LangChain에서 제공하는 loadSummarizationChain의 Refine 패턴을 활용하여 긴 대화 내역을 효율적으로 압축하고 정제합니다.
// src/types/conversation.types.ts
export interface ConversationMessage {
role: 'user' | 'assistant';
content: string;
timestamp: Date;
}
export interface ConversationContext {
sessionId: string;
messages: ConversationMessage[];
summary?: string;
}
// src/chains/refine.chain.ts
import { Document } from '@langchain/core/documents';
import { loadSummarizationChain } from 'langchain/chains';
import { PromptTemplate } from '@langchain/core/prompts';
import { BedrockChat } from '@langchain/community/chat_models/bedrock';
import { ConversationContext, ConversationMessage } from '../types/conversation.types';
export class RefineConversationChain {
private model: BedrockChat;
private readonly MAX_MESSAGES = 10; // 최근 N개 메시지만 유지
private readonly TOKEN_LIMIT = 4000; // 대략적인 토큰 제한
constructor(model: BedrockChat) {
this.model = model;
}
/**
* 대화 내역을 refine 방식으로 요약
*/
async refineConversationHistory(
context: ConversationContext
): Promise<string> {
const messages = context.messages;
// 메시지가 적으면 전체 반환
if (messages.length <= 5) {
return this.formatMessages(messages);
}
// 오래된 메시지를 청크로 나눔
const oldMessages = messages.slice(0, -5);
const recentMessages = messages.slice(-5);
// 오래된 메시지를 Document 형식으로 변환
const docs = oldMessages.map(
(msg) =>
new Document({
pageContent: `${msg.role}: ${msg.content}`,
metadata: { timestamp: msg.timestamp },
})
);
// Refine 체인 생성
const chain = loadSummarizationChain(this.model, {
type: 'refine',
questionPrompt: PromptTemplate.fromTemplate(
`다음은 대화 내역의 일부입니다. 이를 간결하게 요약해주세요:
{text}
요약:`
),
refinePrompt: PromptTemplate.fromTemplate(
`기존 요약: {existing_answer}
다음 대화 내용을 추가로 고려하여 요약을 개선해주세요:
{text}
개선된 요약:`
),
});
// 요약 실행
const summary = await chain.invoke({
input_documents: docs,
});
// 요약 + 최근 메시지 결합
const refinedContext = `
[이전 대화 요약]
${summary.text}
[최근 대화]
${this.formatMessages(recentMessages)}
`;
return refinedContext;
}
/**
* 메시지 배열을 텍스트로 포맷팅
*/
private formatMessages(messages: ConversationMessage[]): string {
return messages
.map((msg) => `${msg.role === 'user' ? '사용자' : 'AI'}: ${msg.content}`)
.join('\\\\\\\\\\\\\\\\n');
}
/**
* 새 메시지를 추가하고 필요시 refine 수행
*/
async addMessageAndRefine(
context: ConversationContext,
newMessage: ConversationMessage
): Promise<ConversationContext> {
context.messages.push(newMessage);
// 메시지가 많아지면 refine 수행
if (context.messages.length > this.MAX_MESSAGES) {
const refinedSummary = await this.refineConversationHistory(context);
// 최근 메시지만 유지하고 나머지는 요약으로 대체
const recentMessages = context.messages.slice(-5);
context.summary = refinedSummary;
context.messages = recentMessages;
}
return context;
}
/**
* 전체 컨텍스트를 LLM에 전달할 형식으로 변환
*/
getContextForLLM(context: ConversationContext): string {
if (context.summary) {
return `${context.summary}\\\\\\\\\\\\\\\\n\\\\\\\\\\\\\\\\n[최근 대화]\\\\\\\\\\\\\\\\n${this.formatMessages(
context.messages
)}`;
}
return this.formatMessages(context.messages);
}
}
이 구현의 핵심은 대화 전체를 한 번에 LLM에 전달하는 대신, 컨텍스트를 지능적으로 압축하는 Refine 패턴에 있습니다. 동작 흐름은 크게 세 단계로 나뉩니다.
청크 분할:
대화가 길어지면 토큰 제한을 넘기 쉬운 오래된 메시지와 현재 응답에 필수적인 최근 메시지를 분리합니다.
점진적 요약:
Refine 체인을 사용하여 오래된 메시지 청크들을 순차적으로 처리합니다. 이 과정에서 이전 청크의 요약본을 다음 청크의 입력으로 넣어 맥락을 보존하면서 점진적으로 최종 요약본을 정제합니다.
컨텍스트 결합:
최종적으로 얻은 압축된 요약본과 현재의 응답에 중요한 최근 메시지를 결합하여 LLM에 전달할 최적화된 전체 컨텍스트를 구성합니다.
이 방식을 사용하면 수십 턴의 긴 대화 세션에도 LLM의 토큰 제한 내에서 초기 맥락과 핵심 정보를 효과적으로 유지할 수 있습니다.
6️⃣ 전체 흐름 통합
이제 모든 서비스를 연결해 음성 대화 시스템을 완성합니다.
async function processVoiceConversation(sessionId: string, audioFileUri: string) {
// 1. 음성 → 텍스트 (Transcribe)
const userText = await transcribeAudio(audioFileUri, `job-${Date.now()}`);
// 2. 컨텍스트에 사용자 메시지 추가 (Refine Chain)
await refineChain.addMessageAndRefine(context, {
role: 'user',
content: userText,
timestamp: new Date(),
});
// 3. LLM 응답 생성 (Bedrock)
const aiResponse = await generateResponse(userText, context.messages);
// 4. 컨텍스트에 AI 응답 추가 (Refine Chain)
await refineChain.addMessageAndRefine(context, {
role: 'assistant',
content: aiResponse,
timestamp: new Date(),
});
// 5. 텍스트 → 음성 (Polly)
const audioStream = await synthesizeSpeech(aiResponse);
return { text: aiResponse, audio: audioStream };
}
음성 입력부터 음성 응답까지 이어지는 전체 파이프라인이 완성되었습니다. Transcribe, Refine Chain, Bedrock, Polly의 네 가지 핵심 기술이 5단계의 순차적인 흐름 속에서 유기적으로 연결됩니다. 특히, 중심에는 Refine 체인이 위치하여 긴 대화 컨텍스트를 체계적으로 관리함으로써, 사용자에게 길이와 상관없이 안정적인 대화 경험을 제공합니다.
7️⃣ 서비스 API 및 전체 흐름 구성
실제 서비스에서는 다음과 같은 주요 API 엔드포인트를 통해 사용자 경험을 제공합니다.
POST /sessions- 새 대화 세션 생성:사용자가 대화를 시작할 때 호출되며, 고유한 세션 ID를 발급하여 대화 내역 관리를 위한 기반을 마련합니다.
POST /sessions/:id/voice- 음성 파일 업로드 및 응답:사용자가 녹음된 음성 파일을 전송하면, 백엔드에서는 Transcribe를 거쳐 LLM에 Polly로 합성된 음성 응답을 반환합니다.
POST /sessions/:id/text- 텍스트 입력 및 음성 응답:텍스트 채팅이 필요한 경우 사용딥니다. LLM의 응답을 받아 Polly로 즉시 음성 합성하여 전달합니다.
GET /sessions/:id/history- 대화 내역 조회:특정 세션의 과거 대화 내역을 조회합니다.
음성 파일은 AWS S3에 업로드 방식을 사용하고, 최종 LLM의 응답을 Polly로 합성해 스트리밍으로 전달합니다. 이를 통해 응답 지연을 줄이고 보다 자연스러운 대화 경험을 제공합니다.
4. 퀄리티를 높이는 화룡점정
지금까지 서비스 구현을 위한 기본 단계를 진행했습니다. 이제 실제 프로덕션 환경에서 사용자가 서비스를 끊김 없이 이용할 수 있도록 성능과 안정성을 한 단계 더 끌어올릴 차례입니다.
1️⃣ 응답 속도 개선을 위한 병렬 처리 도입
사용자가 체감하는 지연 시간을 최소화하는 것은 서비스 만족도에 직결됩니다. 이를 위해, 독립적으로 실행 가능한 비동기 작업들을 병렬로 처리하여 전체 응답 시간을 획기적으로 단축하겠습니다.
현재 초기 구현에서는 각 단계를 순차적으로 처리하고 있으며, 이로 인해 약 5~7초의 처리 시간이 발생합니다. 아래는 현재의 순차 처리 방식과 예상 소요 시간입니다.
// 순차 처리 - 약 5~7초 소요
const userText = await transcribeAudio(audioFileUri); // 2-3초
await refineChain.addMessageAndRefine(context, userMessage); // 1-2초
const aiResponse = await generateResponse(userText); // 2-3초
const audioStream = await synthesizeSpeech(aiResponse); // 1-2초
컨텍스트 정리(Refining), 응답 생성(Generating), 그리고 음성 합성(Synthesizing) 등의 독립적인 비동기 작업들을 병렬 처리하도록 로직을 수정했습니다.
async function processVoiceConversationOptimized(sessionId: string, audioFileUri: string) {
// 1. 음성 인식 시작
const userText = await transcribeAudio(audioFileUri, `job-${Date.now()}`);
// 2. 컨텍스트 정리와 LLM 호출을 병렬 처리
const [refinedContext, _] = await Promise.all([
refineChain.addMessageAndRefine(context, {
role: 'user',
content: userText,
timestamp: new Date(),
}),
// 필요시 추가 병렬 작업
]);
// 3. LLM 응답 생성
const aiResponse = await generateResponse(userText, refinedContext.messages);
// 4. 컨텍스트 업데이트와 음성 합성을 병렬 처리
const [updatedContext, audioStream] = await Promise.all([
refineChain.addMessageAndRefine(context, {
role: 'assistant',
content: aiResponse,
timestamp: new Date(),
}),
synthesizeSpeech(aiResponse),
]);
return { text: aiResponse, audio: audioStream };
}
독립적인 작업을 병렬 처리함으로써, 전체 처리 시간을 약 30~40% 단축했습니다.
개선 전: 5~7초
개선 후: 3~4초
병렬 처리로 응답 속도를 개선하는 것은 중요하지만, 작업 간의 의존성을 정확히 파악하지 않으면 데이터 불일치나 Race Condition과 같은 심각한 오류가 발생할 수 있습니다.
☑️ 병렬 처리 시 주의사항
1. 작업 의존성 파악 및 병렬 처리 구간 식별
병렬 처리 도입 시 핵심은 순서가 보장되어야 하거나 동일 리소스에 대한 쓰기가 발생하는 작업을 식별하고 순차 처리하도록 설계하는 것입니다.
✅ 안전한 병렬 처리
두 작업이 서로 다른 리소스를 사용하거나, 한쪽이 읽기 전용인 경우 안전합니다.
// ✅ 안전: 컨텍스트 업데이트와 음성 합성은 독립적
const [updatedContext, audioStream] = await Promise.all([
refineChain.addMessageAndRefine(context, aiMessage), // 컨텍스트에 저장
synthesizeSpeech(aiResponse), // 음성 생성
]);
❌ 위험한 병렬 처리
동일한 리소스에 대해 동시에 쓰기를 시도하거나, 결과가 다음 단계의 입력이 되는 의존성이 있을 때 위험합니다.
// ❌ 위험: LLM 응답을 생성하기 전에 컨텍스트를 병렬로 업데이트하면 순서 꼬임
const [aiResponse, _] = await Promise.all([
generateResponse(userText, context.messages), // context 읽기
refineChain.addMessageAndRefine(context, userMessage) // context 쓰기 - 충돌!
]);
👷 안전한 병렬 처리 원칙
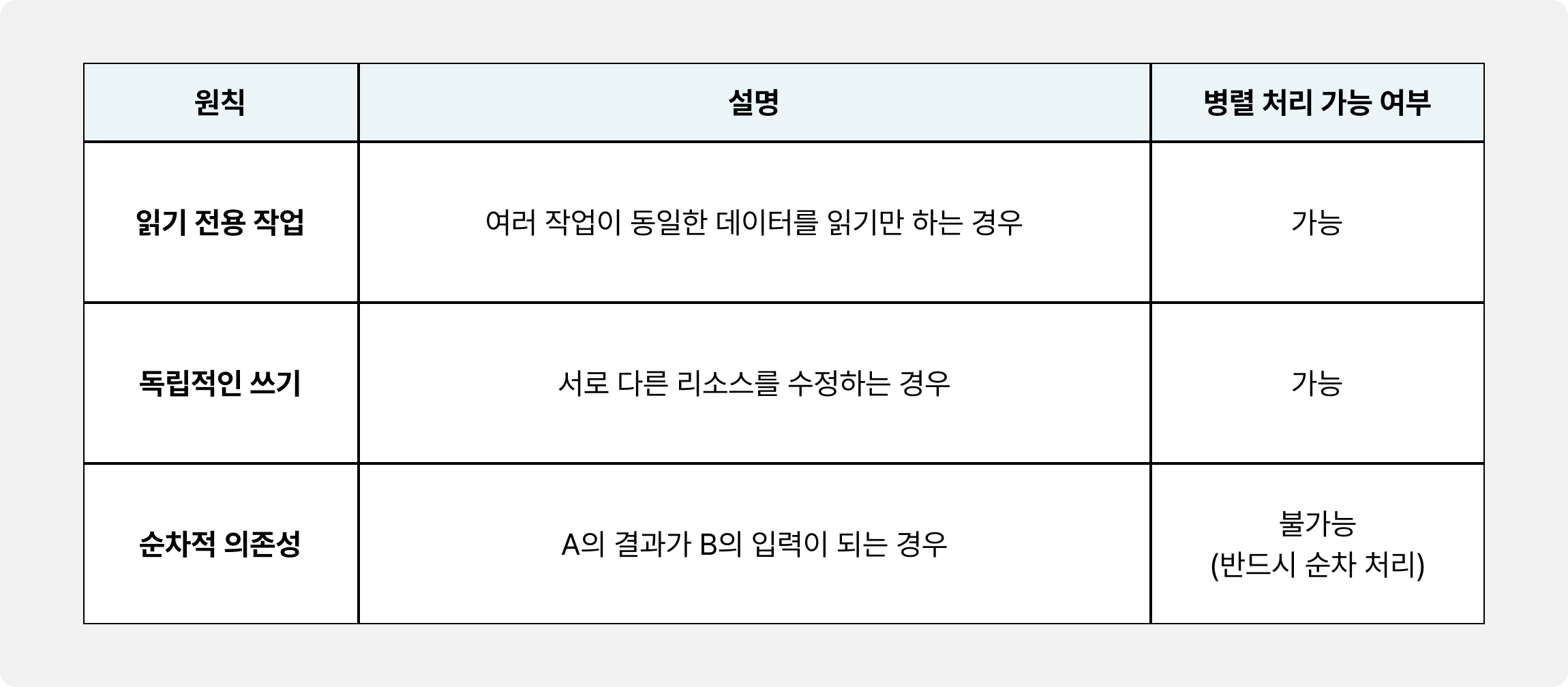
위 코드에서는 addMessageAndRefine과 synthesizeSpeech가 각각 세션 저장소와 Polly API라는 완전히 독립적인 리소스를 사용하므로 안전하게 병렬 처리할 수 있습니다.
2. 실전 안정성 확보
분산 환경(Multi-instance)에서 동일한 세션에 대해 동시 요청이 들어오는 경우, 컨텍스트의 순서가 뒤섞여 대화가 꼬이는 치명적인 문제가 발생할 수 있습니다. 이를 방지하기 위해 세션 기반의 분산 락(Distributed Lock) 메커니즘을 적용합니다.
Redis를 활용하여 특정 세션 ID에 대한 락을 획득한 요청만이 작업을 수행하도록 보장합니다.
class SessionManager {
async withLock<T>(sessionId: string, operation: () => Promise<T>): Promise<T> {
const lockKey = `lock:${sessionId}`;
const lockValue = Date.now().toString();
// 락 획득 시도 (NX: 키가 없을 때만 설정, EX: 자동 만료)
const acquired = await this.redis.set(lockKey, lockValue, 'NX', 'EX', 10);
if (!acquired) {
throw new Error('세션이 다른 요청에서 처리 중입니다');
}
try {
return await operation();
} finally {
// 락 해제 (자신이 설정한 락만 해제)
const currentValue = await this.redis.get(lockKey);
if (currentValue === lockValue) {
await this.redis.del(lockKey);
}
}
}
}
// 사용 예시
await sessionManager.withLock(sessionId, async () => {
return processVoiceConversationOptimized(sessionId, audioFileUri);
});
이렇게 하면 withLock 메커니즘을 통해 동일 세션에 대한 요청이 순차적으로 처리되어 대화 컨텍스트의 순서가 보장됩니다.
2️⃣ 스트리밍 응답 도입으로 사용자 체감 속도 극대화
앞서 병렬 처리로 전체 응답 시간을 줄였지만, 여전히 LLM이 전체 응답을 생성하고 음성 합성이 완료될 때까지 사용자는 기다려야 합니다. 이 대기 시간을 없애기 위해 스트리밍(Streaming) 기법을 도입하여 사용자 체감 응답 속도를 극적으로 개선합니다.
LLM의 응답을 청크 단위로 실시간 스트리밍 받아 텍스트 청크가 생성될 때마다 즉시 음성으로 변환해 사용자 체감 응답 속도를 개선하겠습니다.
async function* streamVoiceResponse(userText: string, context: ConversationContext) {
// LLM 스트리밍 응답
const stream = await model.stream([
new SystemMessage('당신은 친절한 AI 어시스턴트입니다.'),
...context.messages.map(msg =>
msg.role === 'user' ? new HumanMessage(msg.content) : new AIMessage(msg.content)
),
new HumanMessage(userText),
]);
let fullResponse = '';
let textBuffer = '';
for await (const chunk of stream) {
const text = chunk.content as string;
fullResponse += text;
textBuffer += text;
// 문장 ���위로 음성 합성 (마침표, 물음표, 느낌표 기준)
if (/[.?!]\\\\\\\\s*$/.test(textBuffer)) {
const audioStream = await synthesizeSpeech(textBuffer);
yield { text: textBuffer, audio: audioStream };
textBuffer = '';
}
}
// 남은 텍스트 처리
if (textBuffer) {
const audioStream = await synthesizeSpeech(textBuffer);
yield { text: textBuffer, audio: audioStream };
}
// 전체 응답을 컨텍스트에 저장
await refineChain.addMessageAndRefine(context, {
role: 'assistant',
content: fullResponse,
timestamp: new Date(),
});
}
LLM이 생성하는 청크는 매우 작으므로, 청크 하나당 음성 합성을 요청하면 비효율적입니다. 위 코드처럼 마침표(.), 물음표(?), 느낌표(!) 등 문장 종결 기호를 기준으로 텍스트를 모아(buffering) 음성 합성을 요청함으로써 TTS 품질과 API 호출 효율성을 동시에 확보합니다.
LLM 응답 스트리밍을 통해 첫 응답까지의 시간이 획기적으로 단축되었습니다.
개선 전(병렬 처리 후): 3초
개선 후(스트리밍 적용): 1~1.5초(사용자 체감 속도 50-60% 단축)
3️⃣ Redis를 활용한 분산 세션 관리
응답 속도를 개선했다면, 서비스의 안정성과 효율성을 확보해 완성도를 더욱 높여보겠습니다.
여러 서버 인스턴스에서 대화 세션 상태를 공유하고 메모리 사용 효율을 높이기 위해 인메모리 데이터 저장소인 Redis를 활용합니다. 이를 통해 무상태(Stateless) 웹 서버 구조를 유지하면서도 대화 컨텍스트를 안정적으로 관리할 수 있습니다.
import { Redis } from 'ioredis';
class SessionManager {
private redis: Redis;
private readonly SESSION_TTL = 3600; // 1시간
constructor() {
this.redis = new Redis({
host: process.env.REDIS_HOST,
port: parseInt(process.env.REDIS_PORT || '6379'),
});
}
async saveSession(sessionId: string, context: ConversationContext): Promise<void> {
const key = `session:${sessionId}`;
await this.redis.setex(
key,
this.SESSION_TTL,
JSON.stringify(context)
);
}
async getSession(sessionId: string): Promise<ConversationContext | null> {
const key = `session:${sessionId}`;
const data = await this.redis.get(key);
if (!data) return null;
// 활성 세션의 TTL을 연장하여 세션이 유지되도록 합니다.
await this.redis.expire(key, this.SESSION_TTL);
return JSON.parse(data);
}
async deleteSession(sessionId: string): Promise<void> {
await this.redis.del(`session:${sessionId}`);
}
}
Redis를 세션 저장소로 도입함으로써 서버가 여러 대인 분산 환경에서도 대화 컨텍스트가 꼬이지 않고 세션이 완벽하게 공유됩니다. 덕분에 사용자의 요청이 어떤 서버로 가든 이전 대화 내용을 정확하게 기억할 수 있게 되었습니다.
또한, 일정 시간 동안 사용하지 않은 세션은 메모리에서 자동으로 깔끔하게 정리되어 메모리 사용량을 최적화하는 핵심 역할을 합니다. 마지막으로 혹시 모를 서버 장애나 재시작 상황이 발생하더라도, 중요한 대화 기록은 독립적인 Redis에 안전하게 보관되어 세션이 유실될 걱정 없이 서비스를 계속 이어나갈 수 있게 되었습니다.
4️⃣ 에러 복원력 확보: 지수 백오프 재시도 로직
외부 서비스(AWS API, LLM API 등) 호출은 네트워크 문제나 일시적인 서비스 장애로 실패할 수 있습니다. 서비스의 신뢰성(Reliability)을 높이기 위해 지수 백오프(Exponential Backoff)를 적용한 재시도(Retry) 로직을 구현합니다.
async function withRetry<T>(
operation: () => Promise<T>,
maxRetries: number = 3,
baseDelay: number = 1000
): Promise<T> {
for (let attempt = 0; attempt < maxRetries; attempt++) {
try {
return await operation();
} catch (error) {
const isLastAttempt = attempt === maxRetries - 1;
if (isLastAttempt) {
throw error;
}
// 지수 백오프 계산 (1초 → 2초 → 4초)
const delay = baseDelay * Math.pow(2, attempt);
console.warn(`작업 실패, ${delay}ms 후 재시도 (${attempt + 1}/${maxRetries})`, error);
await new Promise(resolve => setTimeout(resolve, delay));
}
}
throw new Error('최대 재시도 횟수 초과');
}
// 사용 예시
async function transcribeAudioWithRetry(audioFileUri: string, jobName: string) {
return withRetry(
() => transcribeAudio(audioFileUri, jobName),
3, // 최대 3회 재시도
1000 // 초기 딜레이 1초
);
}
이 로직을 통해 작은 문제에도 쉽게 무너지지 않은 튼튼한 복원력을 갖출 수 있는데요. 일시적인 네트워크 오류나 서비스 장애가 발생하더라도, 자동으로 잠시 기다린 후 다시 시도하기 때문에 사용자 경험이 끊기지 않고 안정적으로 보호됩니다.
5️⃣ Refine 파라미터 튜닝
대화 컨텍스트를 관리하는 Refine 체인의 MAX_MESSAGES와 TOKEN_LIMIT 값은 성능, 비용, 그리고 대화 품질에 직접적인 영향을 미칩니다. 서비스의 목적에 맞춰 이 파라미터들을 튜닝하여 균형점을 찾아야 합니다.
export class RefineConversationChain {
// 기본값 - 범용적 사용
private readonly MAX_MESSAGES = 10;
private readonly TOKEN_LIMIT = 4000;
// 짧은 대화 최적화 (빠른 응답, 낮은 비용)
// private readonly MAX_MESSAGES = 6;
// private readonly TOKEN_LIMIT = 2000;
// 긴 대화 최적화 (높은 컨텍스트 품질)
// private readonly MAX_MESSAGES = 15;
// private readonly TOKEN_LIMIT = 6000;
}
Refine 체인에서 사용하는 MAX_MESSAGES와 TOKEN_LIMIT은 우리 AI 어시스턴트의 기억력과 집중력을 결정하는 핵심 스위치입니다. 이 스위치를 어떻게 조작하느냐에 따라 AI의 응답 속도, 품질, 그리고 서비스 비용까지 크게 달라질 수 있습니다.

다음은 서비스 목적에 따른 MAX_MESSAGES 추천 값입니다.
짧은 질의 응답: 6~8턴
일반 상담: 10~12턴
긴 대화/교육: 15~20턴
지금까지 AWS Bedrock, Polly, Transcribe를 활용하여 음성 기반 AI 대화 서비스를 구축하는 방법을 살펴보았습니다. 프로젝트 초기에는 단순히 세 가지 핵심 서비스를 연결하면 끝날 거라 생각했지만, 실제 구현에 들어가 보니 가장 큰 도전 과제는 대화 컨텍스트 관리였습니다.
대화가 몇 턴만 길어져도 LLM의 토큰 제한에 걸리면서, AI가 이전의 중요한 맥락을 잊어버리는 문제가 발생했습니다. 마치 AI가 단기 기억 상실증에 걸린 것 같은 느낌이었죠.
이 문제를 해결하기 위해 다양한 컨텍스트 관리 전략을 실험한 결과, Refine 방식이 대화의 순서와 맥락을 가장 효과적으로 유지하면서도 토큰 제한 문제를 깔끔하게 해결해 주는 최적의 방법임을 확인했습니다. 또한 성능 최적화 과정에서 병렬 처리와 스트리밍 응답의 중요성을 직접 체감할 수 있었습니다.
현재 구현을 바탕으로 앞으로는 다음과 같은 개선 사항도 고려하고 있습니다:
실시간 음성 인식: Transcribe Streaming을 활용한 즉시 응답
WebSocket 통신: 양방향 실시간 대화 지원
멀티모달 지원: 텍스트, 이미지, 음성을 결합한 상호작용
감정 분석: 음성 톤 분석을 통한 감정 인식 및 맞춤 응답
다국어 지원: Polly와 Transcribe의 다양한 언어 옵션 활용
AWS의 AI/ML 서비스는 지속적으로 발전하고 있으며, 관리형 서비스를 활용하면 복잡한 AI 애플리케이션도 비교적 쉽게 구축할 수 있습니다. 특히 인프라 관리 부담 없이 확장 가능한 서비스를 만들 수 있다는 점이 큰 장점입니다.
이번 해커톤을 통해 AI 기술을 실제로 적용해보며, 기술적 도전과 해결 과정을 직접 경험할 수 있었습니다. 음성 기반 서비스를 개발하는 분들에게 이 글이 참고가 되길 바랍니다.
-
Written by 홍종혁 | 비누커머스 백엔드 개발자
새로운 변화와 도전을 즐기는 백엔드 개발자 홍종혁 입니다.